Einleitung: Kann ein Bot mein eigenes Spiel spielen?
Die Frage kam mir vor einem Jahr: Kann ein KI-Bot lernen, mein eigenes Spiel zu spielen?
Die Antwort ist ja – und es war eine verrückte Reise. In diesem Artikel zeige ich dir, wie aus einer einfachen Idee ein vollständiges Idle-Spiel mit Machine Learning wurde.
Was du lernen wirst:
- ✅ Wie ein RL-Bot im Browser funktioniert
- ✅ Welche Techniken ich für das Training-System genutzt habe
- ✅ Welche Lessons Learned ich aus der Entwicklung ziehe
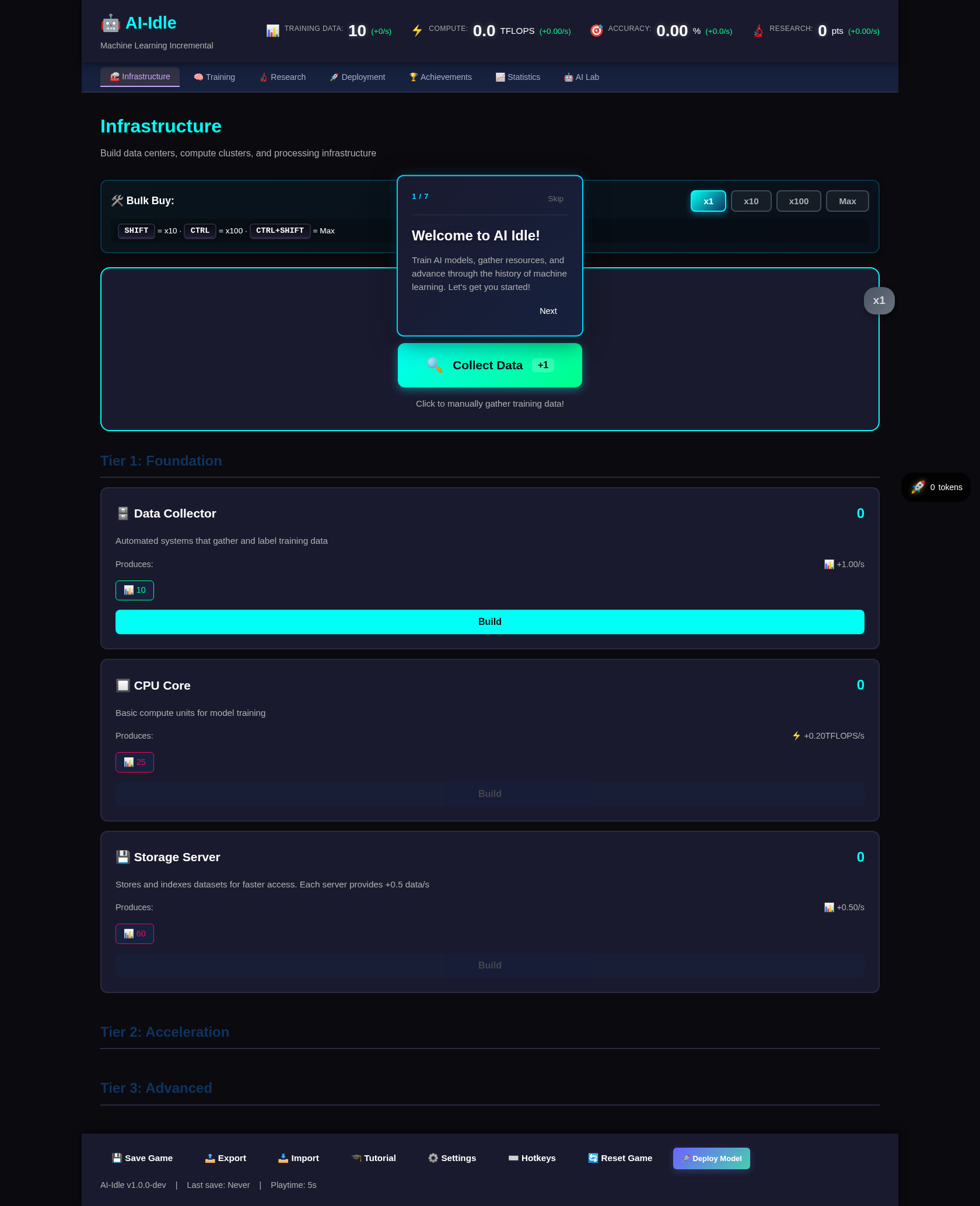
Das Konzept: ML-Modelle trainieren im Browser
AI-Idle startete als Experiment. Das Prinzip ist simpel:
- Sammle Daten – Automatisch oder manuell
- Trainiere Modelle – Von Digits erkennen bis zu Large Language Models
- Forsche – Neue Techniken freischalten
- Deploye – Verdiene Tokens durch erfolgreiche Modelle
Das Besondere: Ein Reinforcement Learning Agent lernt, all das automatisch zu machen.
Die Technik: So funktioniert das Spiel
Über 25 ML-Modelle
Das Spiel bietet Modelle in sechs Kategorien:
- Basic: Digit Recognition, Image Classification
- Intermediate: NLP Model, RL Agent, LLM
- Advanced: Speech Recognition, TTS, VAE, GAN
- Specialized: Semantic Segmentation, Face Recognition
- Expert: Sentiment Analysis, QA, Code Generation
Jedes Modell hat eigene Trainingszeiten, Kosten und Accuracy-Gewinne.
Der RL-Bot: DQN im Browser
Der Bot nutzt Deep Q-Learning mit etwa 47 möglichen Aktionen:
| Aktion | Beschreibung |
|---|---|
| BUILD | 9 Gebäude + 3 Cloud Provider |
| TRAIN | 6 Modellkategorien |
| RESEARCH | 60 Forschungspunkte |
| DEPLOY | 3 Strategien (Fast, Standard, Complete) |
| SHOP | Token-Einlösung |
Der Bot lernt durch Belohnungen: Mehr Fortschritt = höhere Belohnung.
Die Reise: Von 0.1.0 zu 1.0.0
| Version | Meilenstein |
|---|---|
| 0.6.0 | Deployment System – Modelle erfolgreich deployen |
| 0.7.0 | RL Bot – Der DQN-Agent lernt spielen |
| 0.8.0 | UI Refactor – Themes, Mobile, Barrierefreiheit |
| 0.9.0 | Model Zoo, Cloud Provider, erweiterte Research |
| 1.0.0 | 50 Achievements, Sound, Tutorial, UI-Polish |
Jede Version brachte neue Features und Verbesserungen.
Praxis-Beispiel: So lernt der Bot
Szenario: Der Bot muss entscheiden, was er als nächstes macht.
Vorher (Zufall): Der Bot baut willkürlich Gebäude und traint zufällige Modelle. Nach 1000 Schritten: ~50 Coins.
Nachher (mit DQN): Der Bot hat gelernt, dass Research → bessere Modelle → mehr Accuracy → mehr Tokens. Nach 1000 Schritten: ~500 Coins.
Learnings: Der Bot findet selbstständig Strategien, die ich als Entwickler nicht vorhersehen konnte.
häufige Fehler vermeiden
❌ Zu komplexes Reward-System
✅ Start einfach: Nur Fortschritt belohnen, später Fehler bestrafen
❌ Zu viele Actions gleichzeitig
✅ Action-Masking nutzen – nur gültige Aktionen erlauben
❌ Im Browser ohne Optimierung
✅ ** requestAnimationFrame + Web Workers für Performance**
Fazit: Der Bot lernt noch
Nach einem Jahr ist AI-Idle ein vollständiges Spiel:
- 25 ML-Modelle
- 18 Gebäude
- 60 Forschungspunkte
- 50 Achievements
- Ein RL-Bot, der immer besser wird
Das Spiel ist Open Source auf GitHub:
👉 github.com/oliverlaudan-ops/AI-Idle
⭐ Stars sind willkommen!
💬 Deine Meinung?
Hast du schon mal ein Spiel mit KI gebaut? Welche Ansätze hast du genutzt?
📌 Weiterführende Ressourcen:
Kommentare